AWS DynamoDBにデータベースを作成し、データを入力する方法メモ
はじめに
今回の記事の目的
AWS上にDynamoDBを作成し、レコード(アイテム)を追加する。 アイテムの追加は、マネジメントコンソールからの実施と、AWS CLIを用いた2つの方法で実施してみる。
DynamoDBとは
DBモデル
- AWSが提供するフルマネージド型のNo SQL データベース。
- キーバリュー型のDBである。
- 日付や時刻の型がない。
- レコード(アイテム)ごとに項目が異なっていても良い。
- Writeは結果整合性モデル(2つのAZに書き込みが終わったら完了扱い)
- Readは結果整合性モデルだが、オプションで強い整合性モデルも利用できる。
NW、性能
- 高可用性(3か所のAZ)
- プロビジョンドスループットといって、事前に必要なキャパシティを設定できる。テーブルごととCRUDごとに設定できる。(例:Read 100、Write 1000)
- VPCに属さない。
- ストレージの上限がない。
- 大量に発生する行動データなどに使われることが多い。
作成するテーブル
以下レイアウトでテーブルを作成する。
| 属性名 | 型 | 説明 | プライマリキー |
|---|---|---|---|
| id | Number | 投稿のID | ○ |
| name | String | 投稿者名 | |
| message | String | 投稿したメッセージ | |
| postat | String | 投稿した日時 |
テーブルの中身は、以下のAWS Lambda講座で例として利用されていたものと基本的に同じ。
AWS Lambdaを活用したサーバレス実践 -第2回- - Schoo(スクー)
テーブルを作成する
AWSマネジメントコンソールから「DynamoDB」を検索し、「テーブルの作成」。
テーブル名設定
現在の AWS アカウントとリージョンで一意である必要がある。
キーの設定
テーブルのキーを設定する。キーにはいくつか種類がある。
パーティションキー
- テーブル作成時に、1つの属性データを選び、パーティションキーにする。
- ソートキーと合わせて、データを一意に特定する。
- パーティションキーごとに、DynamoDB内部でパーティション分けしてデータ管理している。
ソートキー
- テーブル作成時に、パーティションキーのほかに1つの属性データを選び、ソートキーにすることができる。
- パーティションキーと合わせて、データを一意に特定する。
- 同じパーティションキーを持つアイテムのグループでは、アイテムはソートキーを使ってソートされて管理されている。
ローカルセカンダリーインデックス(Local Secondary Index:LSI)
- ソートキー以外で絞込検索を行うインデックス。
- ソートキーを設定していないテーブルには利用できない。
- パーティションキーとソートキーが複合キーになっているテーブルで、パーティションキーとまた別の属性で検索したいとき、その別の属性をLSIにすることで、パーティションキー+LSIという検索ができる。
グローバルセカンダリーインデックス(Global Secondary Index:GSI)
イメージがわかりやすい参考資料
DynamoDBのキー・インデックスについてまとめてみた - Qiita
【参考】テーブル作成画面

アイテムを作成する
マネジメントコンソールで作成
マネジメントコンソールからアイテムを作成できる。
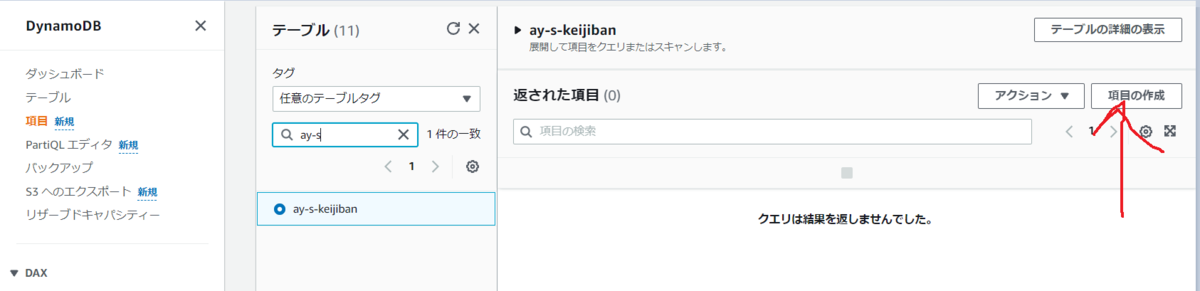
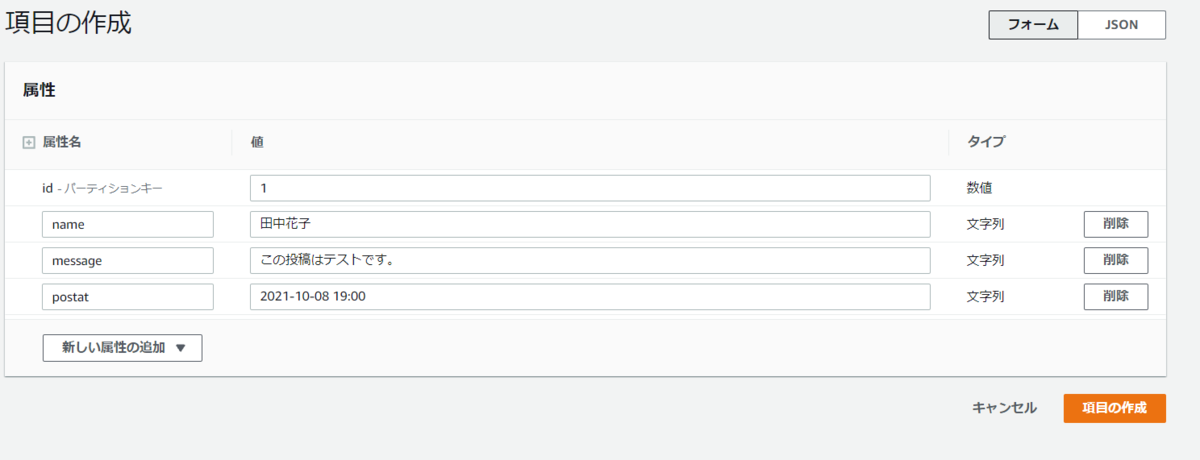
値を入力する。
AWS CLIで作成
AWS CLIの初期設定
以下の記事「AWS CLIの基本設定」を参照。
tomiko0404.hatenablog.com
アイテムの作成コマンド
put-itemメソッドを使う。
構文は以下。
$ put-item
--table-name <value>
--item <value>
[--expected <value>]
[--return-values <value>]
[--return-consumed-capacity <value>]
[--return-item-collection-metrics <value>]
[--conditional-operator <value>]
[--condition-expression <value>]
[--expression-attribute-names <value>]
[--expression-attribute-values <value>]
[--cli-input-json | --cli-input-yaml]
[--generate-cli-skeleton <value>]
公式リファレンス
put-item — AWS CLI 2.2.44 Command Reference
itemオプションに設定するデータ形式
itemオプションに実際の値を入れていくが、以下のような形で、通常のJSONを設定してもデータ投入できない。
# NG例 { "id": 2, "name": "CLI子2丁目", "message": "AWSCLIからput-item。JSONの中に改行の\\を入れると良くないらしい。", "postat": "2021-10-09 4:00" }
DynamoDB特有のJSON構文で記載する必要がある。
# OK例 { "id": { "N": "2" }, "name": { "S": "CLI子2丁目" }, "message": { "S": "AWSCLIからput-item。JSONの中に改行の\\を入れると良くないらしい。" }, "postat": { "S": "2021-10-09 4:00" } }
このJSONの構文としては、
"項目名" : { "データ型" : "実際の値"}
となる。データ型は、
- N :数値
- S :文字列
- B :バイナリ
- SS :文字列配列
- NS :数字配列
など。
データ型が「数値」であっても、JSON上は""で囲む点に注意。
詳細は公式ドキュメント参照。
put-item — AWS CLI 2.2.44 Command Reference
各データ型の説明:
命名ルールおよびデータ型 - Amazon DynamoDB
最終的にコマンドラインで実行するのは以下のコマンド。
$ aws dynamodb put-item \
--table-name ay-s-keijiban \
--item '{
"id": { "N": "2" },
"name": { "S": "CLI子2丁目" },
"message": { "S": "AWSCLIからput-item。JSONの中に改行の\\を入れると良くないらしい。" },
"postat": { "S": "2021-10-09 4:00" }
}' \
--return-consumed-capacity TOTAL
\ はコマンド中での改行を意味する(Linux一般)。
注意:JSON中に\を記載するとうまくいかない。
公式ドキュメントだとJson中にも\を書いているようなのだが。
また、--return-consumed-capacity TOTALは
消費された書き込み容量単位の総数を返します。
とのこと。コマンドの応答として以下が返却された。
{
"ConsumedCapacity": {
"TableName": "ay-s-keijiban",
"CapacityUnits": 1.0
}
}
アイテムを追加した結果
GUI、CLIの2つの方法でアイテムを追加することができた。
ちなみに、マネジメントコンソールで作成したデータは、その後の手順で同じidとなるデータを上書きしてしまい、消えてしまっている。

おわりに
DynamoDBのテーブルを作成し、アイテムを追加することができた。